上周,两款未署名的匿名模型悄然登陆知名 API 聚合平台 OpenRouter,代号分别为「Hunter Alpha」与「Healer Alpha」。它们未作任何公开宣传,调用量却以异常速度持续攀升。
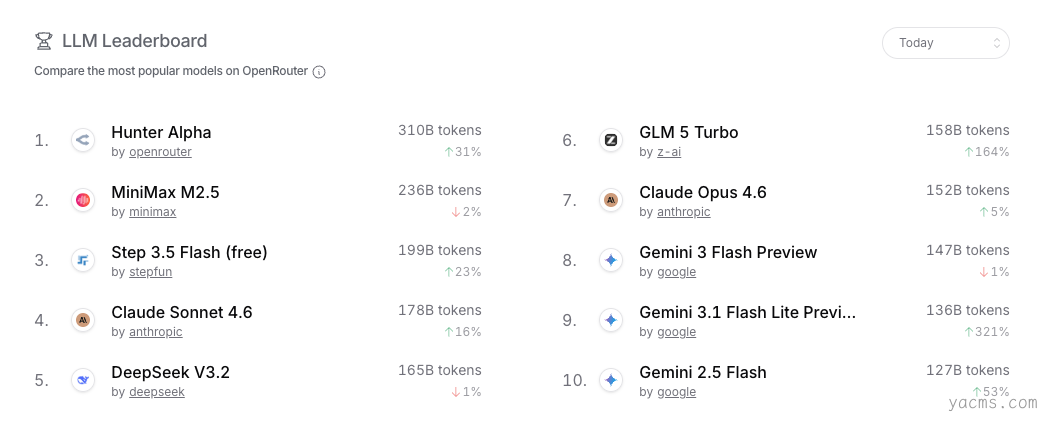
其中,Hunter Alpha 更是在多日内登顶平台日榜,累计调用量突破 1T tokens,引发社区广泛猜测。主流观点一度指向 DeepSeek,认为这可能是其 V4 版本的内测模型。

OpenClaw 创始人 Peter Steinberger 在 X 平台上的公开询问,进一步点燃了社区的讨论热情。谜底于近日揭晓:小米官方正式宣布,Hunter Alpha 与 Healer Alpha 均为其 MiMo-V2 系列大模型的早期内测版本。与此同时,小米 MiMo 大模型负责人罗福莉也在 X 平台公开认领。
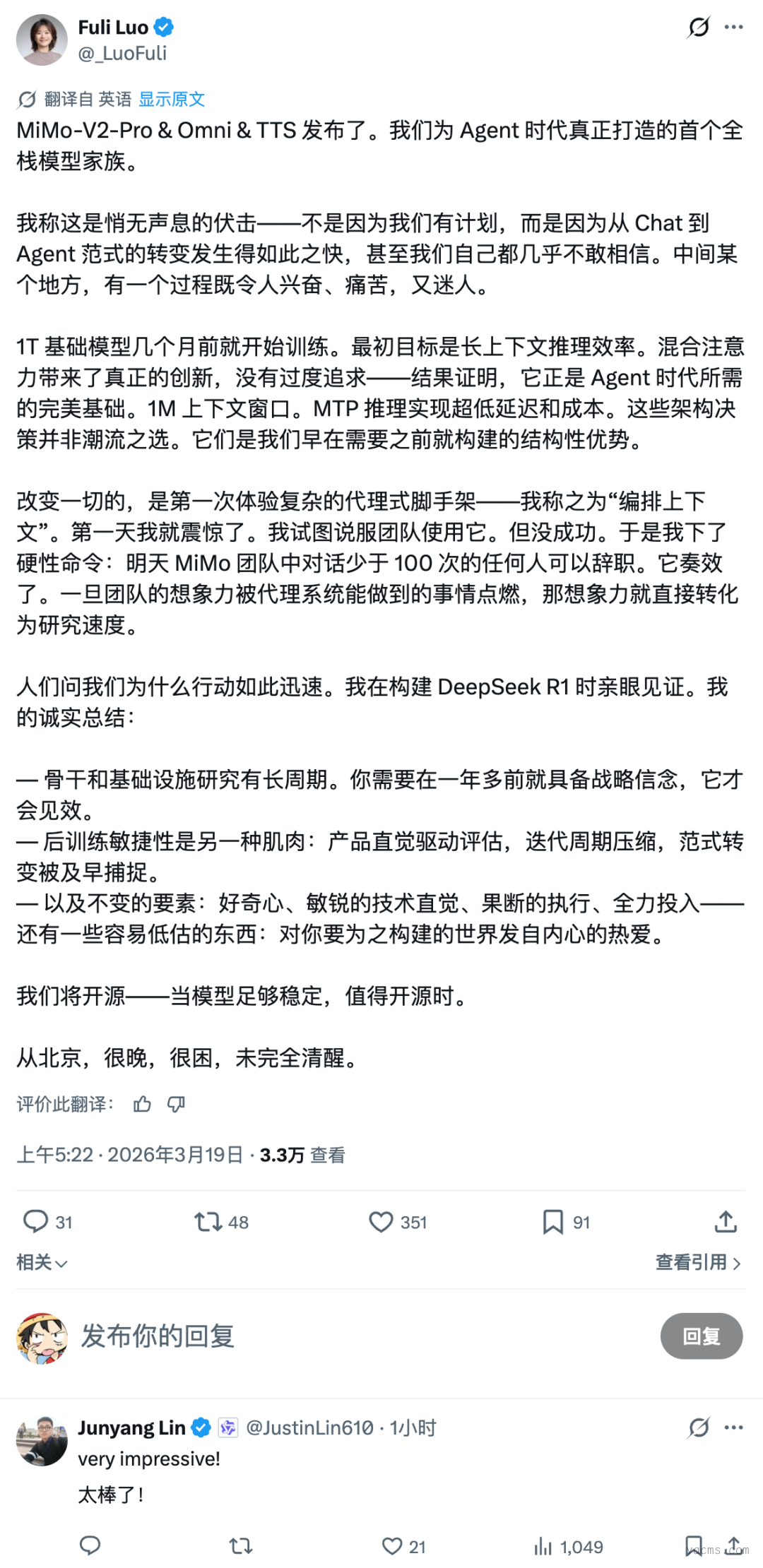
上下滑动查看更多内容,林俊旸也现身评论区
值得一提的是,罗福莉此前正是 DeepSeek 的研究员。换言之,这位来自 DeepSeek 的专家,在小米主导开发了一款被全网误认为是 DeepSeek 的模型。

此次小米一次性发布三款模型,虽功能各有侧重,但共同指向一个核心目标:推动 AI 从“会对话”向“能完成任务”的智能体(Agent)范式演进:
- MiMo-V2-Pro:旗舰文本基座模型,专为高强度 Agent 工作流设计,主打复杂推理、任务规划与工具调用能力。
- MiMo-V2-Omni:全模态 Agent 基座模型,原生融合文本、视觉与音频感知,旨在打通从环境理解到自主执行的完整链路。
- MiMo-V2-TTS:语音合成大模型,致力于为 Agent 赋予富有情感与温度的声音表达能力,构成全栈能力的最后一环。
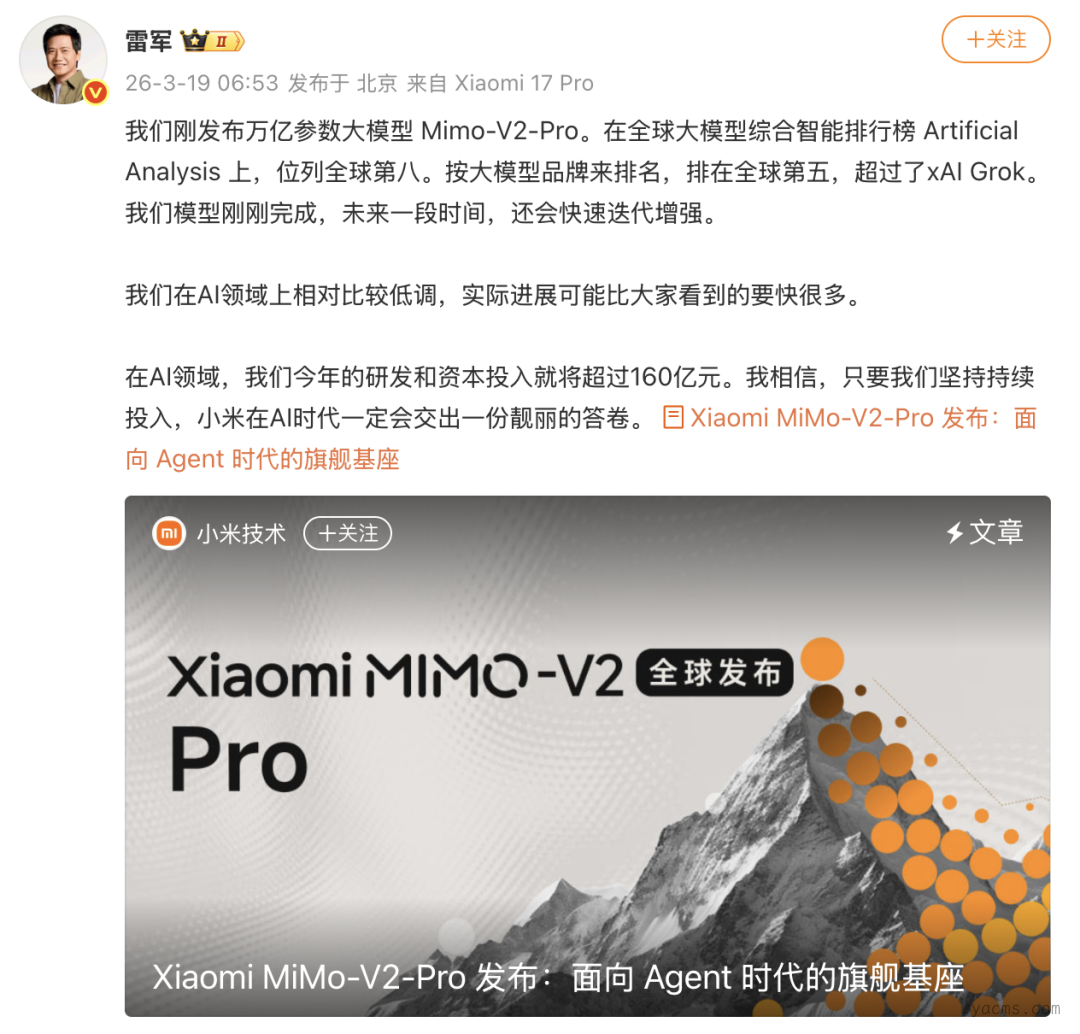
MiMo-V2-Pro:高性价比的推理引擎
MiMo-V2-Pro 总参数量突破 1T,激活参数量为 42B,较前代 MiMo-V2-Flash 提升约 3 倍。参数量增长并未牺牲推理效率,这得益于其创新的混合注意力架构(Hybrid Attention)。该架构的混合比例从前代的 5:1 优化至 7:1,并引入轻量级 MTP(Multi Token Prediction)层以加速实际生成速度。同时,模型支持高达 1M 的超长上下文窗口,在处理长序列 Agent 任务时具备结构性优势。
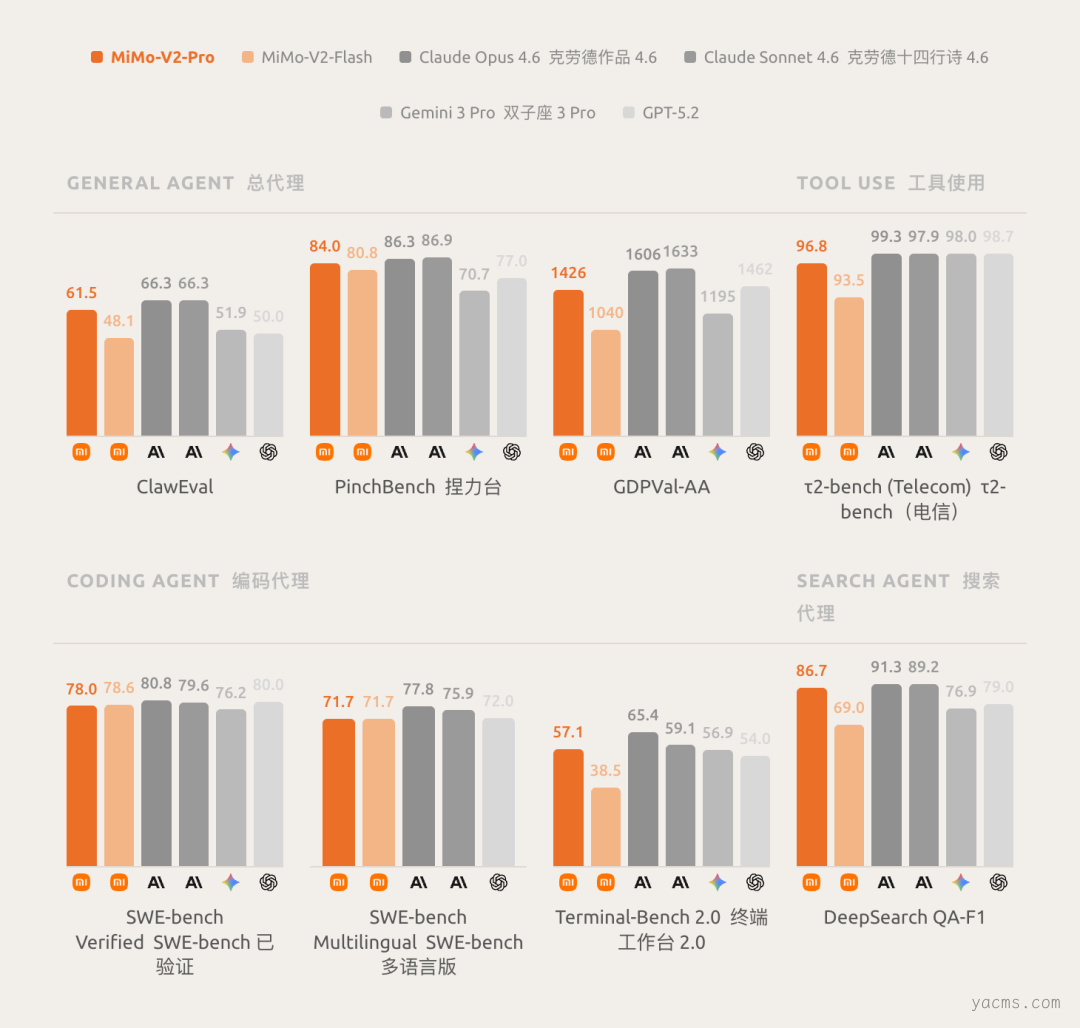
在全球权威大模型综合评测榜 Artificial Analysis 上,MiMo-V2-Pro 目前位列全球第八、国内第二。
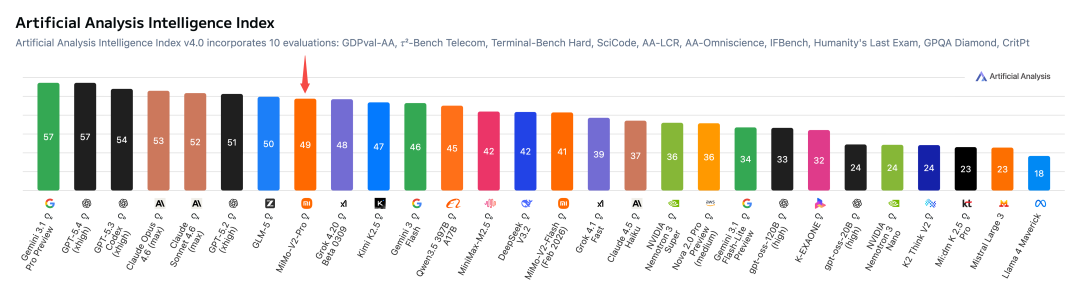
除基准测试外,小米更强调模型的“实际体感”。在 Coding Agent、通用 Agent 及工具调用等维度,MiMo-V2-Pro 与 Claude Sonnet 4.6 处于同一梯队。据小米内部深度评测,其代码工程能力已接近 Claude Opus 4.6,并展现出更优的系统设计能力与代码风格。Hunter Alpha 匿名内测期间,调用量最高的应用多为编程工具,这从市场层面直接验证了其能力。
在 OpenClaw 框架中,MiMo-V2-Pro 还展示了前端开发能力,能够一步生成兼具视觉美感与功能完备性的网页。

定价方面,MiMo-V2-Pro 的 API 价格仅为同级别竞品的五分之一。具体为:256K 上下文内,输入每百万 tokens 1 美元,输出 3 美元;1M 上下文内,输入 2 美元,输出 6 美元。这一策略明确显示了小米希望通过价格优势快速渗透开发者生态的决心。
为此,小米联合 OpenClaw、OpenCode、KiloCode、Blackbox 及 Cline 五大 Agent 框架团队,提供为期一周的限时免费接口支持。各框架具体限免信息可关注 MiMo 官方及开放平台公告。
目前,MiMo-V2-Pro 已正式开放 API 服务,开发者可前往 https://platform.xiaomimimo.com 接入。官方模型体验页面 https://aistudio.xiaomimimo.com 同步上线了 MiMo Claw 功能,支持免费体验其 Agent 能力。
MiMo-V2-Omni:统一感知与行动的全模态基座
如果说 MiMo-V2-Pro 是强大的“大脑”,那么 MiMo-V2-Omni 的野心在于为这个大脑同时赋予“眼睛”、“耳朵”和“手”。它是小米首个在基座层面统一感知与行动的全模态模型,从底层实现了文本、视觉与音频的深度融合。
音频理解是其差异化优势之一。模型支持超过 10 小时的连续长音频理解,覆盖从环境声分类到多说话人分离的复杂场景,综合表现超越 Gemini 3 Pro。图像理解方面,其在多学科视觉推理与复杂图表分析上超越 Claude Opus 4.6,逼近 Gemini 3 Pro 等顶尖闭源模型水平。
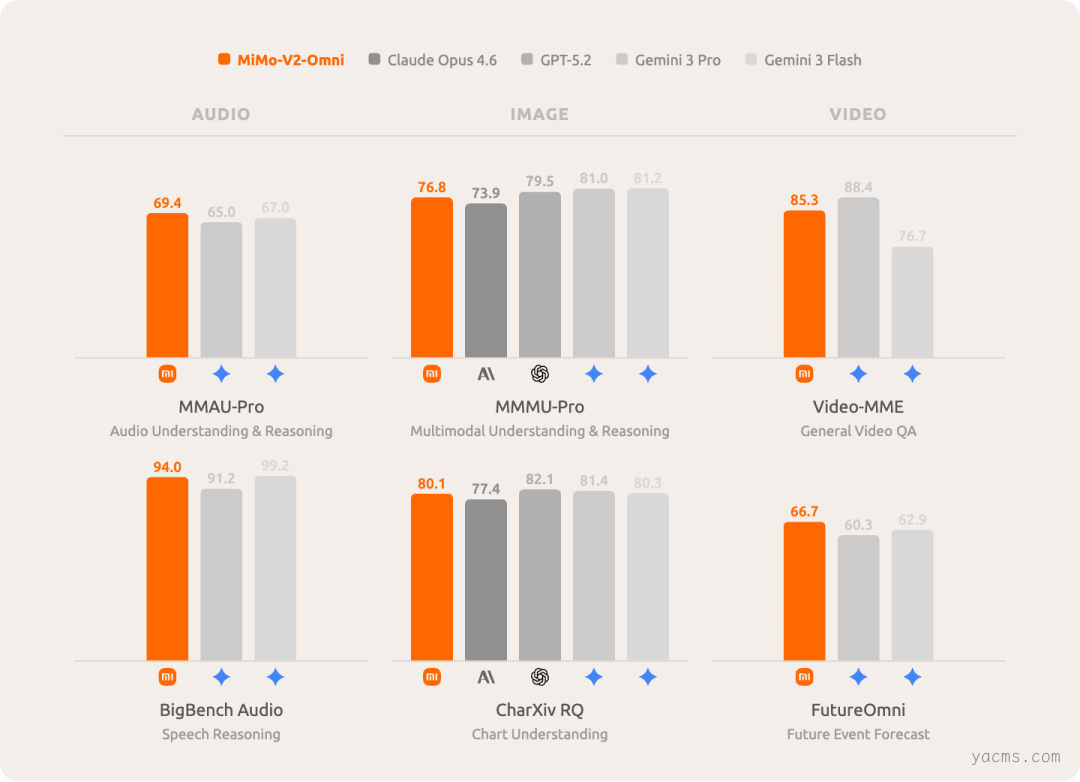
视频理解支持原生音视频联合输入,而非分离处理,在架构层面实现了真正的多模态理解。
在 Agent 实操中,MiMo-V2-Omni 展现出强大的端到端任务完成能力。例如,结合 OpenClaw 框架,它可以像真人一样操控浏览器:在社交媒体查阅评测、整理建议、进行跨店比价、联系客服议价直至完成下单,并能灵活应对多标签页切换等实时交互需求。
在纯文本智能体任务上,MiMo-V2-Omni 同样保持高度竞争力,在 OpenClaw 的 PinchBench 榜单上表现比肩 Gemini 3 Pro。
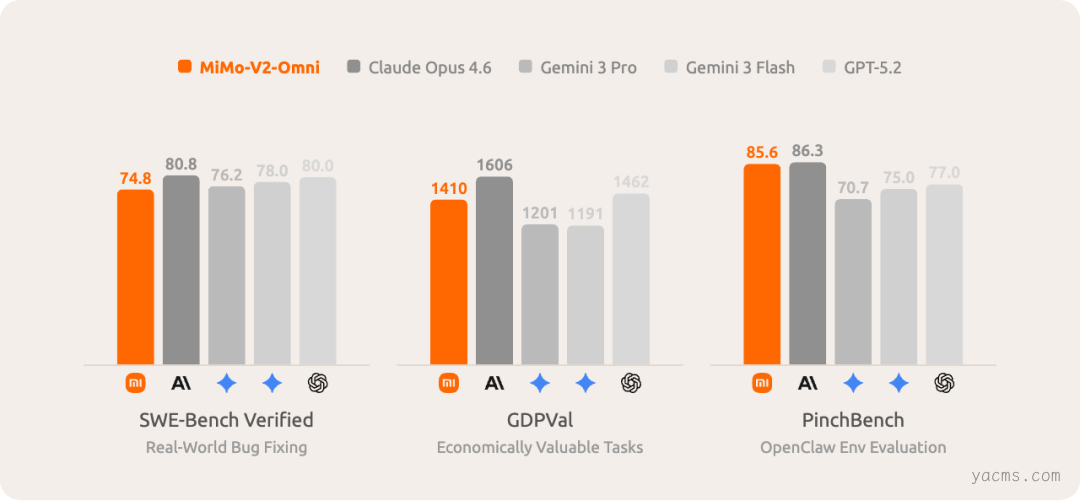
Healer Alpha 匿名内测期间,该模型在 PinchBench 上取得均分第一,社区好评与基准测试结果形成了双向印证。
办公场景方面,MiMo-V2-Omni 已与金山办公合作,接入 WPS 灵犀,支持直接生成高质量的 Word 文档、结构化 Excel、规范排版的 PDF 与完整 PPT。MiMo Studio 的 Claw 模块也已全面打通金山 WebOffice 生态,原生支持四大主流文档格式。
WPS 灵犀体验地址:lingxi.wps.cn
MiMo-V2-Omni 已开放 API,支持 256K 上下文,输入定价为每百万 tokens 0.4 美元,输出 2 美元,接入地址同上。
MiMo-V2-TTS:富有表现力的情感语音
一个完整的 Agent 不仅需要思考和行动,还需要能够“开口说话”。MiMo-V2-TTS 正是为此而生。
该模型基于小米自研的 Audio Tokenizer 和多码本语音文本联合建模架构,经过上亿小时语音数据的大规模预训练。海量的数据覆盖了极为丰富的说话风格、口音与场景,为模型的泛化能力奠定了基础。
在多维度强化学习后训练阶段,模型围绕韵律自然度、音质稳定性、音色克隆质量与场景语气适配等维度持续优化。得益于多层码本建模架构,强化学习可以直接利用语音相关的奖励信号进行优化,而非依赖间接的文本反馈,使得多维奖励能更有效地指导生成过程。
MiMo-V2-TTS 支持从整体基调到句内局部情绪的多粒度控制,能在同一句话内实现语气转折与情感递变,这在同类产品中较为罕见。模型能智能识别标点、语气词、强调标记等格式信号,并自动转化为自然的语音表达,无需用户手动标注。
其方言支持涵盖东北话、四川话、河南话、粤语、台湾腔等,同时具备角色扮演式风格演绎与高质量歌声合成能力,实现了“能说、能演、也能唱”的多样化表达。
官方表示,未来 MiMo-V2-TTS 将与 MiMo-V2-Omni 深度融合,让 Agent 不仅能理解世界,更能用富有表现力的声音去讲述世界。



评论
发表评论