Claude官方承认Claude Code质量下滑 公布原因已修复并为订阅者重置额度
Claude 发布官方报告,承认过去一个月 Claude Code 质量下滑,发布事后分析报告指出三个问题:默认推理努力从高降至中、缓存优化 bug 导致遗忘、系统提示词限制冗长导致编码质量下降,已在 v2.1.116+ 版本全部修复。
问题仅限于 Claude Code 和 Agent SDK,未影响核心模型或 API,公司已为所有订阅者重置使用限额,并计划加强内部狗粮测试、评估系统和渐进式变更流程。以下为报告正文。
在过去一个月里,我们一直在调查部分用户反馈的 Claude 回复质量下降问题。我们最终将这些报告追溯到 3 个彼此独立的变更,它们分别影响了 Claude Code、Claude Agent SDK 和 Claude Cowork。API 没有受到影响。
截至 4 月 20 日(v2.1.116),这 3 个问题都已经修复。
这篇文章会说明我们发现了什么、修复了什么,以及接下来会做哪些改变,以确保类似问题再次发生的概率显著降低。
我们非常严肃地对待这类性能或质量退化报告。我们从不会故意削弱模型能力,而且我们也第一时间确认 API 和推理层没有受到影响。
经过调查,我们识别出 3 个不同的问题:
3 月 4 日,我们将 Claude Code 的默认 reasoning effort 从 high 调整为 medium,以降低部分用户在 high 模式下遇到的超长延迟,这种延迟严重时会让 UI 看起来像是卡死了。这个取舍是错误的。用户告诉我们,他们更希望默认得到更高智能水平,只在简单任务里主动切换到更低 effort。我们因此在 4 月 7 日回滚了这一改动。这个问题影响了 Sonnet 4.6 和 Opus 4.6。
3 月 26 日,我们上线了一个改动:对于闲置超过 1 小时的会话,清除 Claude 较早的思考内容,以降低用户重新进入会话时的延迟。由于一个 bug,这个清理动作没有只执行一次,而是在该会话后续的每一轮都持续触发,导致 Claude 看起来健忘且重复。我们在 4 月 10 日修复了这个问题。这个问题影响了 Sonnet 4.6 和 Opus 4.6。
4 月 16 日,我们在 system prompt 中新增了一条降低冗长度的指令。它与其他 prompt 改动叠加后,伤害了编码质量,因此我们在 4 月 20 日回滚了它。这个问题影响了 Sonnet 4.6、Opus 4.6 和 Opus 4.7。
由于这 3 个改动分别作用于不同流量切片,并且生效时间也不同,整体表现就像一种广泛但并不一致的退化。虽然我们从 3 月初就开始调查这些报告,但一开始很难把它们和用户反馈中的正常波动区分开来,而且我们内部的使用情况和评测最初都没有复现出后来确认的这些问题。
这不是用户应该从 Claude Code 获得的体验。截至 2026 年 4 月 23 日,我们正在为所有订阅用户重置使用额度。
调整 Claude Code 的默认 reasoning effort
我们在 2 月发布 Claude Code 中的 Opus 4.6 时,将默认 reasoning effort 设为 high。
发布后不久,我们收到用户反馈,表示 Claude Opus 4.6 在 high effort 模式下偶尔会思考过久,导致 UI 看起来像是冻结,并给这些用户带来不成比例的延迟和 token 消耗。
一般来说,模型思考越久,输出效果就越好。Claude Code 用 effort level 让用户自行设定这个取舍,也就是更多思考,还是更低延迟和更少触发使用限制。我们在为模型校准 effort level 时,会综合考虑这种权衡,从 test-time-compute 曲线上选出能为用户提供最佳选择范围的几个点。在产品层面,我们再决定默认使用曲线上的哪个点,并把该值作为 effort 参数发送给 Messages API;其他选项则通过 /effort 提供给用户。
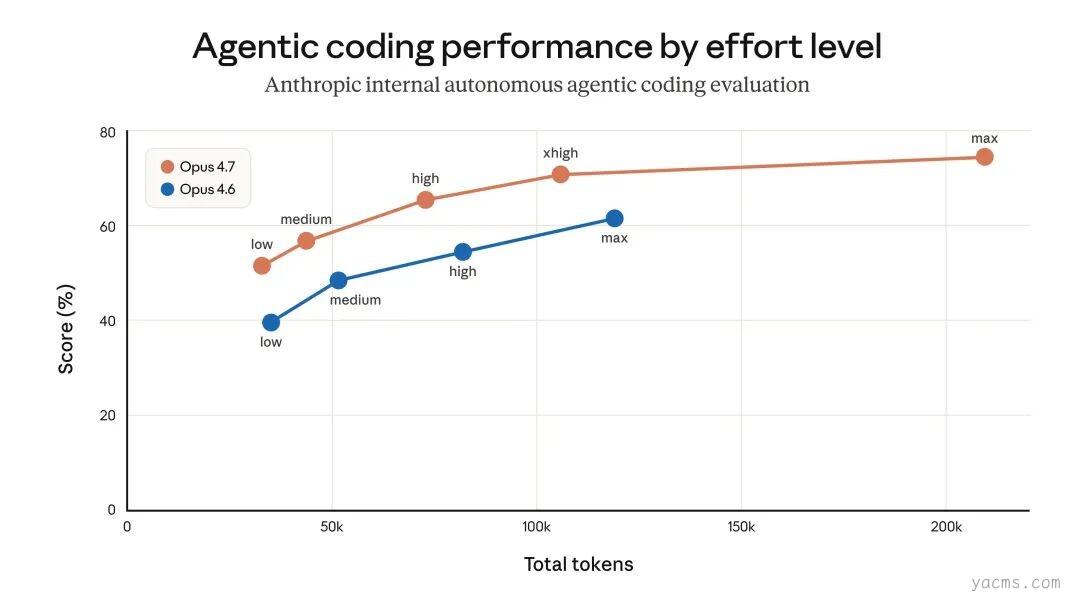
在内部评测和测试中,medium effort 在绝大多数任务上只带来轻微的智能下降,却显著降低了延迟。它也没有出现同样的超长尾思考延迟问题,并且有助于最大化用户的使用额度。因此,我们上线了将 medium 设为默认 effort 的改动,并通过产品内弹窗解释了这一决定的原因。
上线后不久,用户开始反馈 Claude Code 变得没那么聪明。我们做了多轮设计迭代,希望让当前 effort 设置更清晰,从而提醒用户他们可以修改默认值,包括启动提示、内联 effort selector,以及重新引入 ultrathink,但大多数用户仍然保留了 medium 这个默认设置。
在听取更多客户反馈后,我们于 4 月 7 日撤销了这一决定。
现在,所有用户在使用 Opus 4.7 时默认采用 xhigh effort,其他所有模型默认采用 high effort。
一次丢失历史推理内容的缓存优化
当 Claude 为某个任务进行推理时,这段推理通常会保留在对话历史中,这样在之后的每一轮里,Claude 都能看到自己为什么做出某些编辑和工具调用。
3 月 26 日,我们上线了一项原本旨在提升效率的改动。我们使用 prompt caching,让连续的 API 调用对用户来说更便宜也更快。Claude 发起 API 请求时,会把输入 token 写入缓存;在一段时间没有活动后,该 prompt 会被逐出缓存,为其他 prompt 腾出空间。缓存利用率是我们非常谨慎管理的一项指标,关于这一点可以参考我们的做法说明
这个设计本来应该很简单:
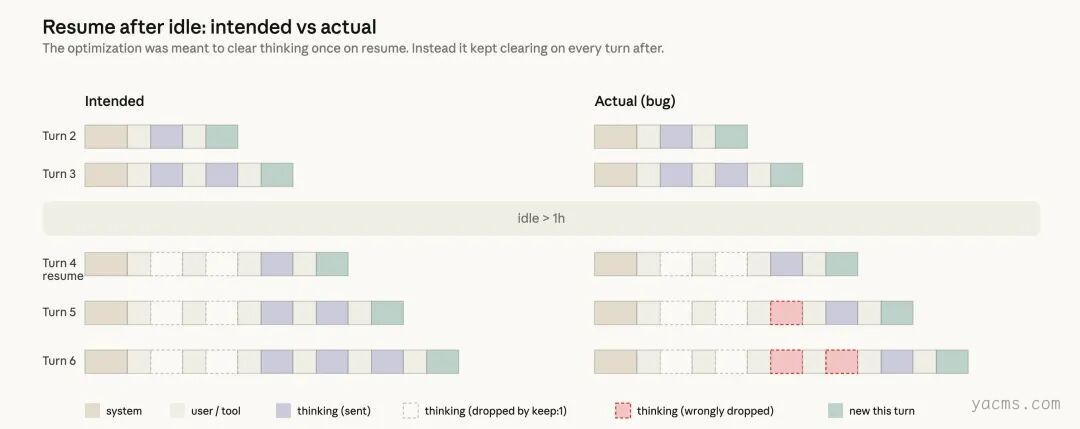
如果一个会话已经闲置超过 1 小时,我们可以在用户恢复会话时清除旧的 thinking 段落,从而降低恢复成本。既然这次请求本来也会因为缓存失效而成为 cache miss,我们就可以从请求中裁掉不必要的消息,减少发送给 API 的未缓存 token 数量。
随后,我们再继续发送完整的推理历史。为此,我们使用了 clear_thinking_20251015 API header,并配合 keep:1。
但实现里有一个 bug。它不是只清理一次 thinking history,而是在该会话剩余的每一轮都持续清理。也就是说,一旦某个会话跨过了闲置阈值,后续这个进程中的每一个请求都会告诉 API:只保留最近的一段推理块,丢弃它之前的所有内容。这个问题会不断叠加。如果你在 Claude 正在执行某个工具调用时发送一条跟进消息,那么在这个错误标记下就会开启新一轮处理,结果连当前这一轮的推理也会被丢掉。Claude 仍会继续执行,但会越来越不记得自己为什么选择当前的行为。这最终表现为用户报告中的健忘、重复,以及奇怪的工具选择。
由于后续请求会持续丢弃 thinking block,这些请求也会不断触发 cache miss。我们认为,这就是另一个独立问题的来源,也就是用户报告中使用额度消耗速度比预期更快。
还有两个无关实验,让我们一开始更难复现这个问题:一个是只在内部启用、与消息队列有关的服务端实验;
另一个是 thinking 展示方式上的正交改动,它在大多数 CLI 会话里掩盖了这个 bug,因此即便我们测试了外部构建版本,也没有及时抓到它。
这个 bug 处在 Claude Code 的上下文管理、Anthropic API 和 extended thinking 的交叉点上。它涉及的改动通过了多轮人工和自动化代码审查,也通过了单元测试、端到端测试、自动验证以及 dogfooding。再加上它只发生在一个边角场景里,也就是陈旧会话,以及复现本身又比较困难,所以我们花了一周多时间才定位并确认根因。
在调查过程中,我们用 Opus 4.7 对相关问题 PR 进行了回测式 Code Review[2]。在提供了足够完整的代码仓库上下文后,Opus 4.7 找出了这个 bug,而 Opus 4.6 没有。为了避免类似问题再次发生,我们现在正在为代码审查补充对更多仓库上下文的支持。
我们在 4 月 10 日发布的 v2.1.101 中修复了这个 bug。
一项用于降低冗长度的 system prompt 改动
我们的最新模型 Claude Opus 4.7,相比前代有一个明显的行为特征:
正如我们在发布时提到过的[3],它往往相当啰嗦。这会让它在复杂问题上更聪明,但也会产出更多输出 token。
在发布 Opus 4.7 前几周,我们就开始为 Claude Code 做调优准备。
每个模型的行为都有细微差异,而我们会在每次发布前花时间优化对应的 harness 和产品层行为。
我们有多种手段来降低冗长度,包括模型训练、prompt 调优,以及改进产品里的 thinking UX。
最终这些方法我们都用了,但加入 system prompt 的其中一条新指令,对 Claude Code 的智能表现产生了过大的负面影响:
“Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.”
在经过数周内部测试,并且我们运行的那组评测中没有发现退化后,我们对这个改动有足够信心,于是在 4 月 16 日随 Opus 4.7 一起发布了它。
作为这次调查的一部分,我们又做了更多 ablation,也就是逐行移除 system prompt 中的指令,来理解每一行的具体影响,并使用了一组覆盖面更广的评测。其中一项评测显示,Opus 4.6 和 4.7 都下降了 3%。因此我们在 4 月 20 日发布时立即回滚了这条 prompt。
后续改进
为了避免这些问题再次发生,我们会做出几项改变:
确保更大比例的内部员工使用与公众完全一致的 Claude Code 构建版本,而不是我们内部用于测试新功能的版本;
同时也会改进我们内部使用的 Code Review[2] 工具,并把改进后的版本提供给客户。
我们也在对 system prompt 的改动增加更严格的控制。今后,Claude Code 的每一次 system prompt 变更,都会跑一套覆盖面更广、按模型区分的评测;
我们会持续进行 ablation 来理解每一行的影响;
同时我们已经构建了新的工具,让 prompt 改动更容易审查和审计。
除此之外,我们还在 CLAUDE.md 中新增了指导,确保与特定模型相关的改动只会被限定在对应模型上。对于任何可能牺牲智能表现的改动,我们都会增加 soak period、扩大评测集,并采用渐进式 rollout,以便更早发现问题。
我们最近在 X 上创建了 @ClaudeDevs,希望有更多空间详细解释产品决策以及背后的原因。我们也会在 GitHub 的集中讨论串里同步相同的更新。
最后,我们想感谢所有用户。无论是通过 /feedback 命令提交问题,还是在网上发布了具体且可复现的案例,正是这些反馈让我们最终能够识别并修复这些问题。今天,我们正在为所有订阅用户重置使用额度。
评论
发表评论